publications
2026
- Preprint
 Reducing Memorisation in Generative Models via Riemannian Bayesian InferenceJohanna Marie Gegenfurtner*, Albert Kjøller Jacobsen*, Naima Elosegui Borras, and 2 more authorsarXiv preprint, 2026
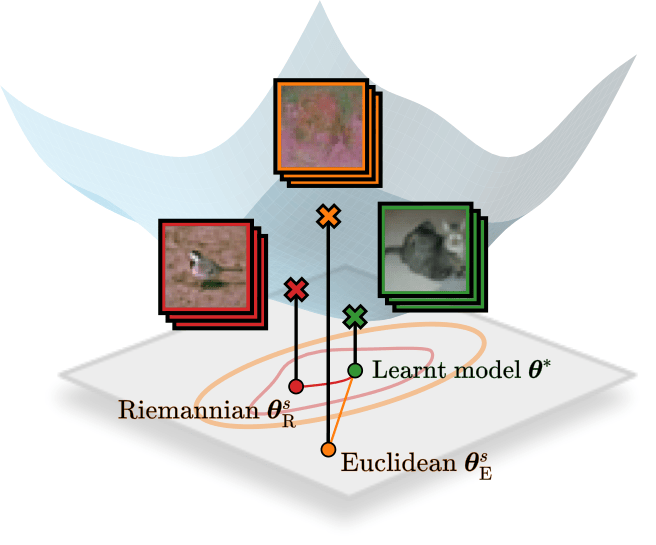
Reducing Memorisation in Generative Models via Riemannian Bayesian InferenceJohanna Marie Gegenfurtner*, Albert Kjøller Jacobsen*, Naima Elosegui Borras, and 2 more authorsarXiv preprint, 2026Modern generative models can produce realistic samples, however, balancing memorisation and generalisation remains an open problem. We approach this challenge from a Bayesian perspective by focusing on the parameter space of flow matching and diffusion models and constructing a predictive posterior that better captures the variability of the data distribution. In particular, we capture the geometry of the loss using a Riemannian metric and leverage a flexible approximate posterior that adapts to the local structure of the loss landscape. This approach allows us to sample generative models that resemble the original model, but exhibit reduced memorisation. Empirically, we demonstrate that the proposed approach reduces memorisation while preserving generalisation. Further, we provide a theoretical analysis of our method, which explains our findings. Overall, our work illustrates how considering the geometry of the loss enables effective use of the parameter space, even for complex high-dimensional generative models.
- NLDL
 Staying on the Manifold: Geometry-Aware Noise InjectionAlbert Kjøller Jacobsen*, Johanna Marie Gegenfurtner*, and Georgios ArvanitidisNorthern Lights Deep Learning Conference (NLDL), 2026
Staying on the Manifold: Geometry-Aware Noise InjectionAlbert Kjøller Jacobsen*, Johanna Marie Gegenfurtner*, and Georgios ArvanitidisNorthern Lights Deep Learning Conference (NLDL), 2026It has been shown that perturbing the input during training implicitly regularises the gradient of the learnt function, leading to smoother models and enhancing generalisation. However, previous research mostly considered the addition of ambient noise in the input space, without considering the underlying structure of the data. In this work, we propose several methods of adding geometry-aware input noise that accounts for the lower dimensional manifold the input space inhabits. We start by projecting ambient Gaussian noise onto the tangent space of the manifold. In a second step, the noise sample is mapped on the manifold via the associated geodesic curve. We also consider Brownian motion noise, which moves in random steps along the manifold. We show that geometry-aware noise leads to improved generalization and robustness to hyperparameter selection on highly curved manifolds, while performing at least as well as training without noise on simpler manifolds. Our proposed framework extends to learned data manifolds.
2025
- EurIPS
 Reducing Memorisation in Generative Models via Riemannian Bayesian InferenceJohanna Marie Gegenfurtner*, Albert Kjøller Jacobsen*, and Georgios ArvanitidisEurIPS - Workshop on Principles of Generative Modeling (PriGM), 2025
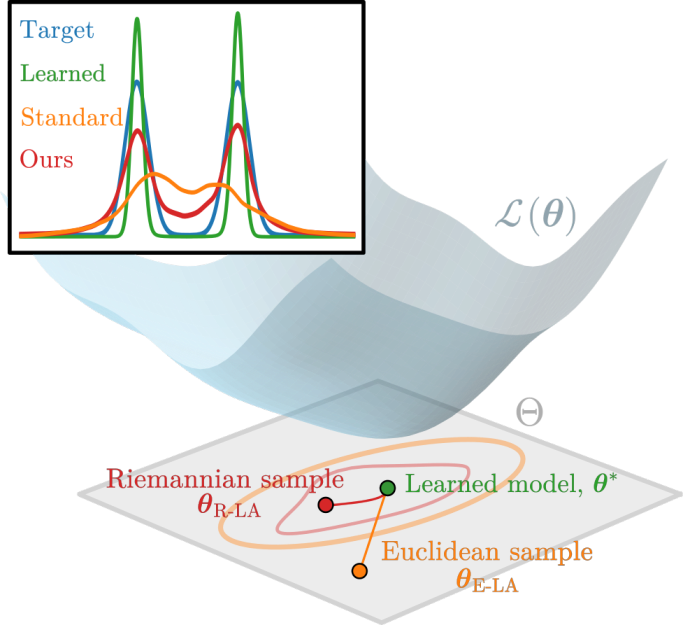
Reducing Memorisation in Generative Models via Riemannian Bayesian InferenceJohanna Marie Gegenfurtner*, Albert Kjøller Jacobsen*, and Georgios ArvanitidisEurIPS - Workshop on Principles of Generative Modeling (PriGM), 2025How to balance memorisation and generalisation in generative models remains an open task. To investigate this, we employ Bayesian methods, which have recently been proposed to predict the uncertainty of generated samples. In our work, we employ the Riemannian Laplace approximation, from which we can sample generative models that resemble the trained one. Our geometry-aware approach yields improved results compared to the Euclidean counterpart.
- Preprint
 Monge SAM: Robust Reparameterization-Invariant Sharpness-Aware Minimization Based on Loss GeometryAlbert Kjøller Jacobsen and Georgios ArvanitidisarXiv preprint, 2025
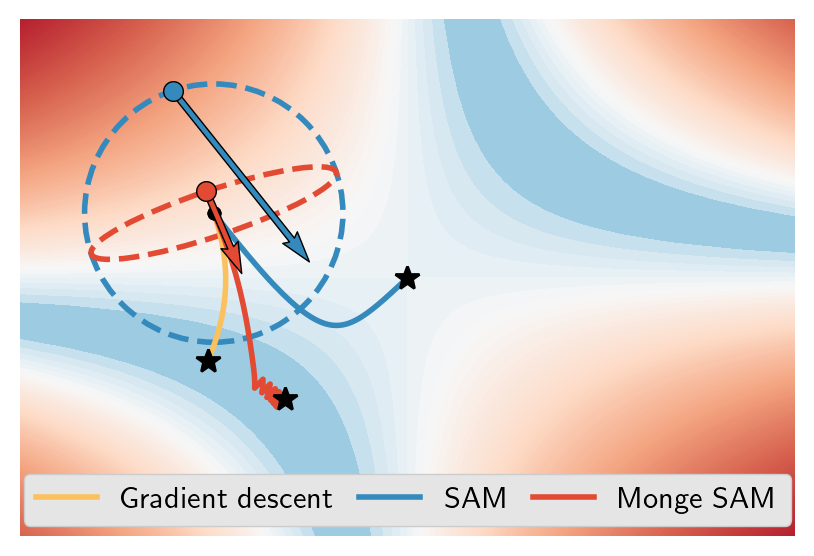
Monge SAM: Robust Reparameterization-Invariant Sharpness-Aware Minimization Based on Loss GeometryAlbert Kjøller Jacobsen and Georgios ArvanitidisarXiv preprint, 2025Recent studies on deep neural networks show that flat minima of the loss landscape correlate with improved generalization. Sharpness-aware minimization (SAM) efficiently finds flat regions by updating the parameters according to the gradient at an adversarial perturbation. The perturbation depends on the Euclidean metric, making SAM non-invariant under reparametrizations, which blurs sharpness and generalization. We propose Monge SAM (M-SAM), a reparametrization invariant version of SAM by considering a Riemannian metric in the parameter space induced naturally by the loss surface. Compared to previous approaches, M-SAM works under any modeling choice, relies only on mild assumptions while being as computationally efficient as SAM. We theoretically argue that M-SAM varies between SAM and gradient descent (GD), which increases robustness to hyperparameter selection and reduces attraction to suboptimal equilibria like saddle points. We demonstrate this behavior both theoretically and empirically on a multi-modal representation alignment task.
- ICASSP
 How Redundant Is the Transformer Stack in Speech Representation Models?Teresa Dorszewski*, Albert Kjøller Jacobsen*, Lenka Tětková, and 1 more authorIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025
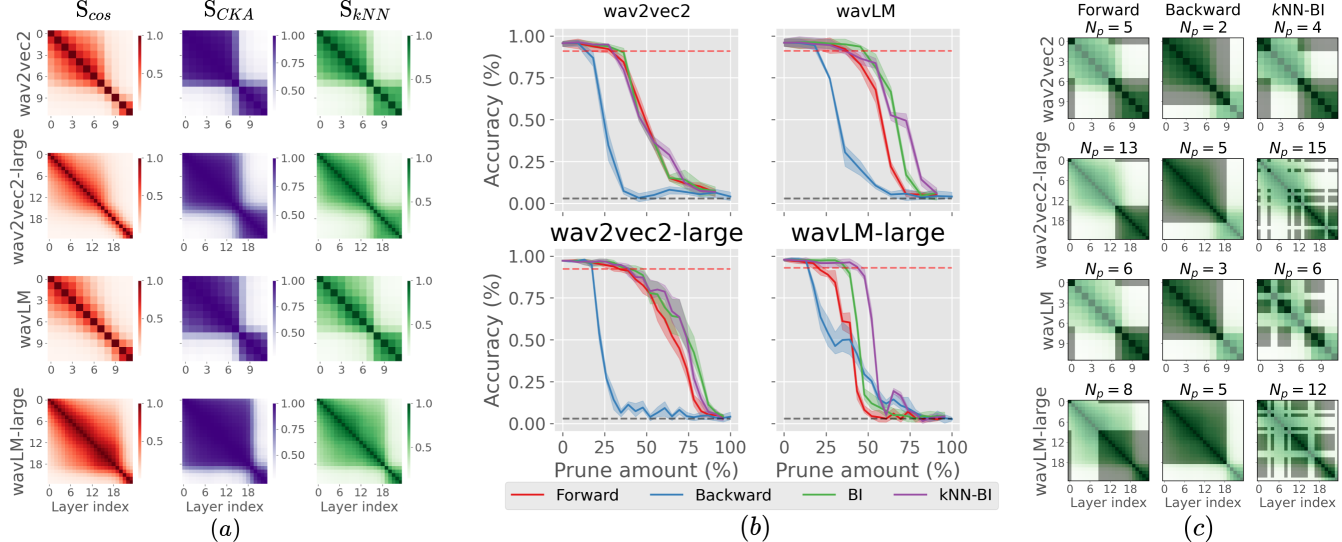
How Redundant Is the Transformer Stack in Speech Representation Models?Teresa Dorszewski*, Albert Kjøller Jacobsen*, Lenka Tětková, and 1 more authorIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025Self-supervised speech representation models, particularly those leveraging transformer architectures, have demonstrated remarkable performance across various tasks such as speech recognition, speaker identification, and emotion detection. Recent studies on transformer models revealed high redundancy between layers and the potential for significant pruning, which we will investigate here for transformer-based speech representation models. We perform a detailed analysis of layer similarity in speech representation models using three similarity metrics: cosine similarity, centered kernel alignment, and mutual nearest-neighbor alignment. Our findings reveal a block-like structure of high similarity, suggesting two main processing steps and significant redundancy of layers. We demonstrate the effectiveness of pruning transformer-based speech representation models without the need for post-training, achieving up to 40% reduction in transformer layers while maintaining over 95% of the model’s predictive capacity. Furthermore, we employ a knowledge distillation method to substitute the entire transformer stack with mimicking layers, reducing the network size by 95-98% and the inference time by up to 94%. This substantial decrease in computational load occurs without considerable performance loss, suggesting that the transformer stack is almost completely redundant for downstream applications of speech representation models.